twittering-mode には、C-c C-l で「λかわいいよλ」と投稿できる、
よく分からない機能がある。たいてい間違って投稿されるのだと思う。w
まあ、OFF にすればいいんだけどね。
よく分からない機能ではあるけど、実際に使ってみるとハングルのような
文字が投稿されてしまう。前から気づいていたんだけど、急に思い立って
調べてみることにした。
調査内容
まず、Emacs23 で再現し、Emacs22 では再現しないことが分かった。
twittering-update-lambda() の
“\xd34b\xd22b\xd26f\xd224\xd224\xd268\xd34b” を評価すると、以下のよ
うに結果が異なる。
Emacs22
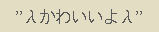
Emacs23

“λ” の上にカーソルを置いて、“C-u C-x =” で文字コードを調べたところ、
Emacs22 は #xd34b で、Emacs23 は #x3bb だった。
mule-ja-2009:09607
で聞いてみたところ、Emacs23 では内部文字コードは
UNICODE になったとのこと。じゃあ Emacs22 はなんだろうと思ってググっ
てみたら、以下の変換式らしいと分かった。
0xc000 + JIS上位バイト*128 + JIS下位バイト
http://www.dennougedougakkai-ndd.org/~delmonta/emacs/27.html
“λ” は JIS コードでは 0x264b、UNICODE(UTF-16) では 0x03bb 。
このことから、Emacs23 の内部文字コードが UNICODE である裏付けが取れた。
では “λ” の JIS コード 0x264b を、Emacs22 の変換式に当てはめてみようか。
0xc000 + (0x26 * 0x80) + 0x4b = 0xd34b
前述の Emacs22 の変換式に間違いはなさそうだ。
さらに半田さんが mule-ja-2009:09610
で Emacs22 の内部文字コードにつ
いて、正確な情報を提供してくれた。すごいなあ。
まとめ
Emacs22 と Emacs23 の内部文字コードは異なる。"\xd34b" のような表記
をするときは、(>= emacs-major-version 23) 等で切り分ける必要があり
そう。twittering-update-jojo() も化けるので、修正する必要あり。
おまけ
“C-u C-x =” で一文字ずつ内部文字コードを調べるのは非効率なので、ま
とめて変換できるコードを作りました。もっと良い方法はあると思います。
(let ((str "λかわいいよλ")
(str2 "") code)
(with-temp-buffer
(insert str)
(goto-char (point-min))
(while (> (point-max) (point))
(setq code (char-after (point)))
(setq str2
(concat str2
(if (>= code 128)
(format "#x%x" code)
(buffer-substring-no-properties (point) (+ (point) 1)))))
(forward-char 1)))
str2)
Emacs23 では上記の場合、"#x3bb#x304b#x308f#x3044#x3044#x3088#x3bb"
が得られ、"#" を全て “" に変換し評価すると、“λかわいいよλ” にな
るはず。最初から “\x3bb” といった出力は出来ないのかなあ。